
Not having a full understanding of what is available to you can come back to haunt you in the long run. I was working with some developers with years of experience developing database applications—on other databases. They built analysis software (trending, reporting, visualization software). It was to work on clinical data related to health care. They were not aware of SQL syntactical features like inline views, analytic functions, and scalar subqueries.
Their major problem was they needed to analyze data from a single parent table to two child tables; an Entity Relation Diagram (ERD) might look like Figure 1-1.

Figure 1-1. Simple ERD
The developers needed to be able to report on the parent record with aggregates from each of the child tables. The databases they worked with in the past did not support subquery factoring (WITH clause), nor did they support inline views—the ability to “query a query” instead of query a table. Not knowing these features existed, they wrote their own database of sorts in the middle tier. They would query the parent table and for each row returned run an aggregate query against each of the child tables. This resulted in their running thousands of tiny queries for each single query the end user wanted to run. Or, they would fetch the entire aggregated child tables into their middle tier into hash tables in memory—and do a hash join.
In short, they were reinventing the database, performing the functional equivalent of a nested loop join or a hash join, without the benefit of temporary tablespaces, sophisticated query optimizers, and the like. They were spending their time developing, designing, fine-tuning, and enhancing software that was trying to do the same thing the database they already bought did! Meanwhile, end users were asking for new features but not getting them, because the bulk of the development time was in this reporting “engine,” which really was a database engine in disguise.
I showed them that they could do things such as join two aggregations together in order to compare data that was stored at different levels of detail. Several approaches are possible, as illustrated in Listings 1-1 through 1-3.
Listing 1-1. Inline Views to Query from a Query

Listing 1-2. Scalar Subqueries That Run Another Query per Row
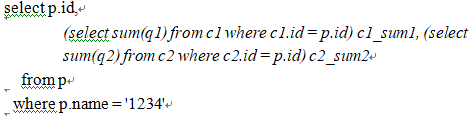
Listing 1-3. Subquery Factoring via the WITH Clause
In addition to what you see in these listings, we can also do great things using the analytic functions like LAG, LEAD, ROW_NUMBER, the ranking functions, and so much more. Rather than spending the rest of the day trying to figure out how to tune their middle tier database engine, we spent the day with the SQL Reference Guide projected on the screen (coupled with SQL*Plus to create ad hoc demonstrations of how things worked). The end goal was no longer tuning the middle tier; now it was turning off the middle tier as quickly as possible.
Here’s another example: I have seen people set up daemon processes in an Oracle database that read messages off of pipes (a database IPC mechanism implemented via DBMS_PIPE). These daemon processes execute the SQL contained within the pipe message and commit the work.
They do this so they could execute auditing and error logging in a transaction that would not get rolled back if the bigger transaction did. Usually, if a trigger or something was used to audit an access to some data, but a statement failed later on, all of the work would be rolled back. So, by sending a message to another process, they could have a separate transaction do the work and commit it.
The audit record would stay around, even if the parent transaction rolled back. In versions of Oracle before Oracle 8i, this was an appropriate (and pretty much the only) way to implement this functionality. When I told them of the database feature called autonomous transactions, they were quite upset with themselves.
Autonomous transactions, implemented with a single line of code, do exactly what they were doing. On the bright side, this meant they could discard a lot of code and not have to maintain it. In addition, the system ran faster overall and was easier to understand. Still, they were upset at the amount of time they had wasted reinventing the wheel. In particular, the developer who wrote the daemon processes was quite upset at having just written a bunch of “shelfware.”
I see examples like these repeated time and time again—large complex solutions to problems that are already solved by the database itself. I’ve been guilty of this myself. I still remember the day when my Oracle sales consultant (I was the customer at the time) walked in and saw me surrounded by a ton of Oracle documentation. I looked up at him and just asked, “Is this all true?” I spent the next couple of days just digging and reading. I had fallen into the trap that I knew all about databases because I had worked with SQL Server, SQL/DS, DB2, Ingress, Sybase, Informix, SQLBase, Oracle, and others. Rather than take the time to see what each had to offer, I would just apply what I knew from the others to whatever I was working on. (Moving to Sybase/SQL Server was the biggest shock to me—it worked nothing like the others at all.) Upon actually discovering what Oracle could do (and the others, to be fair), I started taking advantage of it and was able to move faster, with less code.
Take the time to learn what is available. You miss so much by not doing that. I learn something new about Oracle pretty much every single day. It requires some keeping up with; I still read the documentation.